In a recent learning project i was implementing a XML-parser in c.
After benchmarking my naive implementation on a 12M XML-file i stumbled over something very interesting.
The function using 99% of my time was strlen even though it was only called in a couple of locations.
I could figure out, that it was called on really large substrings for every token.
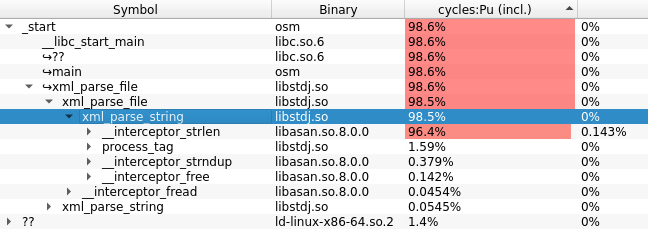
Because i did not really care for the actual length but just compared it
i decided to try out a naive implementation which would directly compare the length of a string
instead of calculating it hoping it would
abort faster than the glibc strlen function takes.
I need to note, that the code was compiled without any optimization and with address sanitizer.
Because I haven't seen this behavior anywhere else addressed, I came up with the following functions.
inline static bool strlen_gt(const char* str, int cmp) { while(*str != '\0') { if(cmp == 0) return true; cmp--; str++; } return false; } inline static bool strlen_ge(const char* str, int cmp) { while(*str != '\0') { if(cmp == 0) return true; cmp--; str++; } return cmp == 0; }
Normal unoptimizeed strlen has the runtime len(str)
whereas this implementation has the runtime min(len(str), cmp).
Especially for cases with really long strings
and smaller values to be compared to the benefits this implementation shine.